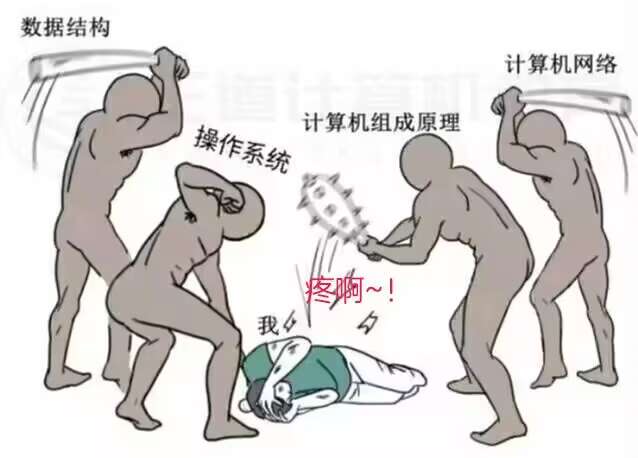
手搓OS-内联汇编
有一说一(起手式),虽然我们在平时写代码时几乎就不会写什么汇编(毕竟咱是写软件的,什么底层,什么硬件就该交给专业的人去搞),但是这对我们阅读代码,理解运行还是很有必要的(我就是想学会)
汇编语言
首先,简单回忆一下汇编语言,虽然这块是真的多,简单总结一下吧。
为了能理解汇编语言的作用方式,我们需要先回忆C语言的运行方式,这个在之前粗浅的写过,C语言要经过预处理-编译-汇编-链接多个步骤,才能形成一个可执行的二进制程序代码。这次不搞hello
world了,换个简单易读的,我们来写一个两个数求和的程序:
1
2
3
4
5
6
7
| #include <stdio.h>
int main(){
int a=0,b=0;
a=b+1;
return 0;
}
|
这套玩法我们其实已经非常熟悉了,编译但不链接,然后反编译:
1
2
3
4
5
6
7
8
9
10
11
| 0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%rbp)
f: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
16: 8b 45 fc mov -0x4(%rbp),%eax
19: 83 c0 01 add $0x1,%eax
1c: 89 45 f8 mov %eax,-0x8(%rbp)
1f: b8 00 00 00 00 mov $0x0,%eax
24: 5d pop %rbp
25: c3 ret
|
因为没有链接,所以实际上程序并没有装入实际内存中,那么拿到的所有内存地址等,都是虚拟的(是一个相对的关系)。跑题了,这个可以后边仔细解释的,先观察整体结构,从左到右,分别是内存地址(姑且这么认为),二进制代码,汇编代码。
汇编语言有很强的平台相关性,也就是换了一个硬件,这个代码的书写方式就完全变了,目前比较流行的有两种格式,分别是intel格式和AT&T格式,我们先不做区分,继续从整体上认识他。
我们知道程序无非是在处理数据,那么我们就可以开始遐(瞎)想了。既然是处理数据,那么数据怎么来,怎么处理,放哪儿处理,怎么处理,处理之后又放哪儿,OK,这下就要去看组成原理了,完结。(bushi)而这种考虑的思路返回到汇编指令上,就形成了这样的一种大体上的汇编指令的格式:
也就是指令+源操作数+目的操作数的一种指令格式,拿来源操作数和目的操作数,加一点神秘的魔法处理,然后把结果送到目的操作数的位置。
接下来,解密操作的数都从哪儿来,当然是——各种各样的寄存器和内存,寄存器包括但不限于:通用寄存器,PC,PSW,栈;
有了这些基本的知识,可以来尝试一下阅读上面的代码了,我们只需要分析这一部分接可以了(用注释给出分析):
1
2
3
4
5
6
| 8: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%rbp) // rbp的前半段存储一个0,实际上就是a变量
f: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp) // rbp的后半段存储一个0,实际上就是b变量
16: 8b 45 fc mov -0x4(%rbp),%eax // 把后半段变脸赋值给通用寄存器eax,即b
19: 83 c0 01 add $0x1,%eax // 将通用寄存器eax中的值与1相加,并存储到eax中,即b+1的过程
1c: 89 45 f8 mov %eax,-0x8(%rbp) // 将eax的值移动到rbp的前半段,a=b+1
1f: b8 00 00 00 00 mov $0x0,%eax // eax置0
|
OK,我知道你看到这里肯定是依旧一头雾水,那就对了,在这里我忽略了所有寄存器细节介绍,也选择性忽略了如何设计直接手写汇编程序,因为这些玩意并不需要我们去写,我们只需要能够读懂就好了。而细节的寄存器的介绍,数据的寻址的介绍,大家可以去看看参考链接的文章,或者去阅读一下指令系统的相关介绍。
内联汇编
进入正题,内联汇编(Inline
assembly)是部分编译器(刚好GCC就支持)支持的一种功能。其将非常低端的汇编语言内嵌在高级语言源始码中。
再开始内联汇编学习前,我们想起来有一种玩意叫做内联函数,内联函数是通过声明(inline)要求编译器在运行时,直接将内联函数的代码复制到调用位置,是一种类似宏的运行方式。内联汇编大抵也如此,不过使用汇编语言写的,声明是asm。
GCC的汇编格式为AT&T格式,具体不再详述,与上面我们所分析的一致。GCC支持两种内联汇编:基本内联汇编和扩展内联汇编
基本内联汇编
基本内联汇编的格式比较简明:
1
| asm[volatile]("assembly code");
|
需要说明的几点:
- 超过一条指令必须通过
\n\t来进行分割
volatile为可选关键字,后面再介绍asm可以换为__asm__,当asm与程序变量有冲突时必须替换
ok,我们先扔掉脑子,来简单玩一玩这个内联汇编
 扔掉脑子
扔掉脑子
1
2
3
4
5
6
7
8
9
| #include<stdio.h>
int main(){
asm("nop");
printf("hello\n");
asm("nop\n\tnop\n\t"
"nop");
return 0;
}
|
一看这个程序就挺抽象的,直接观察结果一定是看不出来的,所以我们还是那一套操作,我们来反编译看汇编代码:
1
2
3
4
5
6
7
| 8: 90 nop
9: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 10 <main+0x10>
10: 48 89 c7 mov %rax,%rdi
13: e8 00 00 00 00 call 18 <main+0x18> // 经典调用指令,这里是调用printf
18: 90 nop
19: 90 nop
1a: 90 nop
|
发现很成功,我们写入的四个气泡指令都在里边,但是什么都不做肯定不是我们编程的初衷,现在我们要玩儿点大的,操作一下变量,玩玩寄存器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #include<stdio.h>
int a=1,b=2,c;
int main(){
asm("movl a,%eax\n\t"
"addl b,%eax\n\t"
"movl %eax,c");
printf("c=%d",c);
return 0;
}
|
老规矩:
1
2
3
4
5
6
7
8
9
| 8: 8b 04 25 00 00 00 00 mov 0x0,%eax
f: 03 04 25 00 00 00 00 add 0x0,%eax
16: 89 04 25 00 00 00 00 mov %eax,0x0
1d: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 23 <main+0x23>
23: 89 c6 mov %eax,%esi
25: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 2c <main+0x2c>
2c: 48 89 c7 mov %rax,%rdi
2f: b8 00 00 00 00 mov $0x0,%eax
34: e8 00 00 00 00 call 39 <main+0x39>
|
可以很清晰的看到我们写的汇编在里边,但是怎么没有数儿呢,因为这些全局变量在内存中和函数并不处于一个区域中。
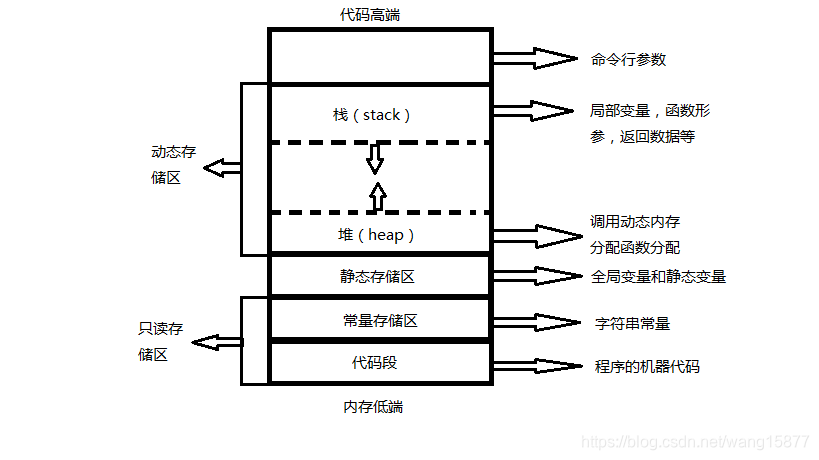 盗了一张图,不想自己画了
盗了一张图,不想自己画了
但是,但是,但是(重要的事情说三遍),有一个很大的问题,因为汇编语言直接操作的是寄存器之类的,如果随随便便更改了某个寄存器的值,而且还没有返回,那么这个程序和你肯定要爆一个。所以一般不用基本内联汇编去搞什么寄存器,而是用扩展内联汇编。
扩展内联汇编
格式:
1
| asm [volatile]("汇编指令": "输出操作数列表" : "输入操作数列表" : "改动的寄存器")
|
啧,看不懂了,这时候需要一些说明:
- 汇编指令:与基本内联汇编格式相同,扩展asm格式中,寄存器前面必须写 2
个%;
- 输出操作数列表:汇编代码如何把处理结果传递给C代码
- 输入操作数列表:C代码如何把数据传递给汇编代码
- 改动的寄存器:使用了哪些寄存器,告诉编译器不要再用这个寄存器,可以省略
先看一个例子:
1
2
3
4
5
6
| int a=10, b;
asm ( "movl %1, %%eax\n\tmovl %%eax, %0"
:"=r"(b)
:"r"(a)
:"%eax"
);
|
ok,现在我们满脑子疑问,我们要带着这些问题接着去学了:
- "b"是什么?
- “r”是什么?
- “=r”是什么?

操作数列表
asm内部使用C语言字符串作为操作数,操作数都要放在双引号中且输出操作数要通过“=”修饰。
1
| "constraint" (C expression)
|
constraint主要用来指定操作数的寻址类型,也用来指明使用哪个寄存器。
与其说是操作数列表,更不如说他是操作数数组,因为在汇编指令中所有的操作数都是以下标的形式给出的(感觉完全可以这么理解)
约束(constraints)
| eax |
a |
| ebx |
b |
| ecx |
c |
| edx |
d |
| 任何通用寄存器 |
r |
| 使用变量的内存位置 |
m |
约束修饰符(Constraint
Modifiers)
| = |
只写 |
| + |
可读写 |
| % |
可以和下一个操作数互换 |
| & |
在内联函数完成之前,可以删除或者重新使用被修饰的操作数 |
ok,又到了扔掉脑子的阶段~
扔掉脑子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #include <stdio.h>
int main()
{
int data1 = 1;
int data2 = 2;
int data3;
asm("movl %%ebx, %%eax\n\t"
"addl %%ecx, %%eax"
: "=a"(data3)
: "b"(data1),"c"(data2));
printf("data3 = %d \n", data3);
return 0;
}
|
老一套,再来一遍,不过这次应该会有明显的区别,大家可以猜一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| d: c7 45 e4 01 00 00 00 movl $0x1,-0x1c(%rbp)
14: c7 45 e8 02 00 00 00 movl $0x2,-0x18(%rbp)
1b: 8b 45 e4 mov -0x1c(%rbp),%eax
1e: 8b 55 e8 mov -0x18(%rbp),%edx
21: 89 c3 mov %eax,%ebx
23: 89 d1 mov %edx,%ecx
25: 89 d8 mov %ebx,%eax
27: 01 c8 add %ecx,%eax
29: 89 45 ec mov %eax,-0x14(%rbp)
2c: 8b 45 ec mov -0x14(%rbp),%eax
2f: 89 c6 mov %eax,%esi
31: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 38 <main+0x38>
38: 48 89 c7 mov %rax,%rdi
3b: b8 00 00 00 00 mov $0x0,%eax
40: e8 00 00 00 00 call 45 <main+0x45>
45: b8 00 00 00 00 mov $0x0,%eax
4a: 48 8b 5d f8 mov -0x8(%rbp),%rbx
|
我们仔细看这几句:
1
2
3
4
| 1b: 8b 45 e4 mov -0x1c(%rbp),%eax
1e: 8b 55 e8 mov -0x18(%rbp),%edx
21: 89 c3 mov %eax,%ebx
23: 89 d1 mov %edx,%ecx
|
虽然GCC的编译状态和我的精神状态一样堪忧,但是很明显啊,这对应的过程就是把data传给我们制定的两个寄存器上,而变化估计大家也能猜到,里边有数据了,大体的原理也应该理解了。
再来玩儿一个内存的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <stdio.h>
int main()
{
int data1 = 1;
int data2 = 2;
int data3;
asm("movl %1, %%eax\n\t"
"addl %2, %%eax\n\t"
"movl %%eax, %0"
: "=m"(data3)
: "m"(data1),"m"(data2));
printf("data3 = %d \n", data3);
return 0;
}
|
先来尝试分析一下:
- 把
data1的数据移到eax中
- 把
data2的数据与eax中的数据相加并存储到eax
- 把
eax里的数据移到data3中
再来看一看汇编代码是不是这么一回事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 1b: c7 45 ec 01 00 00 00 movl $0x1,-0x14(%rbp)
22: c7 45 f0 02 00 00 00 movl $0x2,-0x10(%rbp)
29: 8b 45 ec mov -0x14(%rbp),%eax
2c: 03 45 f0 add -0x10(%rbp),%eax
2f: 89 45 f4 mov %eax,-0xc(%rbp)
32: 8b 45 f4 mov -0xc(%rbp),%eax
35: 89 c6 mov %eax,%esi
37: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 3e <main+0x3e>
3e: 48 89 c7 mov %rax,%rdi
41: b8 00 00 00 00 mov $0x0,%eax
46: e8 00 00 00 00 call 4b <main+0x4b>
4b: b8 00 00 00 00 mov $0x0,%eax
50: 48 8b 55 f8 mov -0x8(%rbp),%rdx
54: 64 48 2b 14 25 28 00 sub %fs:0x28,%rdx
5b: 00 00
5d: 74 05 je 64 <main+0x64>
5f: e8 00 00 00 00 call 64 <main+0x64>
|


volatile
还是那个很典的volatie,一句话:用了volatile保证了顺序性,不给GCC优化
总结
在一个毫无汇编经验的人从0看完,应该对汇编有了大致的了解,而且对于内联汇编这个可以直接玩儿寄存器的玩意也有了一个大概的认识,那就够了,剩下的咱慢慢补(
参考链接
快速入门汇编语言 -
知乎 (zhihu.com)
GCC内联汇编基础 -
简书 (jianshu.com)
内联汇编 - 知乎
(zhihu.com)
内联汇编很可怕吗?看完这篇文章,终结它!
- 知乎 (zhihu.com)