手搓OS-day5
咕咕,做一个老鸽子真的是太舒服了(雾)。这里我先提出一个操作系统公共厕所说()。众所周知,厕所是一种紧俏资源(CPU计算资源),只能独占,这里我们做一个抽(恶)象(心)的假设,人们是可以容忍临时换人的(状态机),有了这个现(逆)实(天)模型,后面就容易理解了。
复习
并发
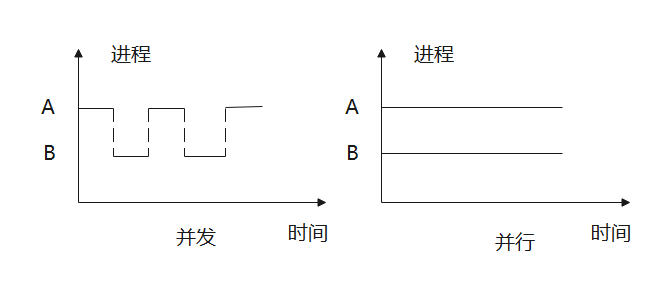
并发,指的是一个时间段内两个进程同时运行(往往是交替的),而不是完全的同时,以人类视角来看并发是相当恶心的,带入一下上边的模型就能体会到。
而与并发常混淆的是并行,并行是我们可以理解的,也就是两个不同的进程(不只是进程)在同时刻处于运行态,但是放在上面的模型中,如果只有一个坑位,显然并行也是不行的,这也就是一般操作系统课程中常常考虑的单处理机。
这里画一个图就懂了:
并发与并行
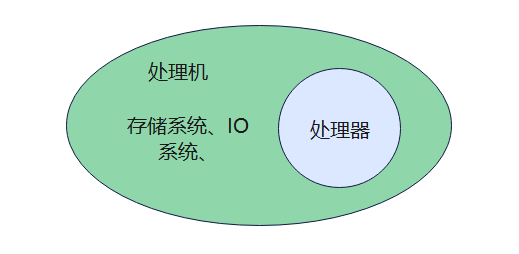
可能有些基础薄弱的同学要问了,处理机和CPU有什么区别吗?
这个还是有一点区别的,处理机,顾名思义,是个处理什么玩意的机器,所以他是处理什么的呢,处理的是数据和程序,实际上,处理机是一个除去外设的一个计算机,而处理器就是CPU,处理机包含处理器:
image-20240114222149946
这个说法在课本上多次提到,我个人认为是很大程度上为我们理解增加了障碍,在操作系统中我们其实就可以狭隘的理解成分配了计算资源(CPU)就好。
并发带来的问题
在上一篇的实验中其实已经能够看出来,由于并发的程序相当随机,所以会出现输出并不符合预期的情况,一般有两种情况:运行顺序不好,访问共同资源,分别对应两种问题:同步与互斥。
今天先来解决互斥问题。
Peterson算法
理论
这个算法相当奇怪,但是是一个礼貌的算法,我们回到上面的厕所模型。厕所里关了(被阿姨锁门且关灯)甲乙两人,甲乙两人都可能想进入厕所(想进厕所是随机的),那怎么才能保证厕所仅仅被一人使用呢?
甲:我想去厕所,但是我得看看乙在不在里边
于是,甲大声且自信的说出,我要去厕所啦,你在用吗,然后乙回复:我正在用,并且听到乙在一直说:我要上厕所,于是甲决定等一会儿,只听见乙还在叫嚷(
没错这个算法就是这么诡异的状况,但是很礼貌,现在我们把这个过程对应到变量上:
1 2 3 4 5 x = 1 ; # 甲表示我要上厕所 turn = B; # 我先问问乙在不在 while (y && turn==B); # 那甲先等会儿# 否则 x = 0 ; # 甲愉快的进入厕所,并结束
这就是Peterson算法的基本流程,如果将其写的更加全面一点:
1 2 3 4 5 6 7 8 9 10 11 void TA () { while (1 ) { x = 1 ; turn = B; while (y && turn == B) ; x = 0 ; } } void TB () { while (1 ) { y = 1 ; turn = A; while (x && turn == A) ; y = 0 ; } }
volatile和编译器屏障(顺序性)
编译器指令重排
根据上一篇的认识,我们已经知道在现代计算机上,程序的执行并不具有原子性,机器语言的顺序与我们写出的高级语言的顺序也会不一致。
1 2 3 4 5 6 7 int a,b;void foo () { a=b+1 ; b=0 ; }
通过我们之前的编译操作和反编译操作:
1 $ gcc -c -o compile1.o compile_demo.c
1 2 3 4 5 6 7 8 9 10 11 12 0000000000000000 <foo>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # e <foo+0xe> e: 83 c0 01 add $0x1,%eax 11: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 17 <foo+0x17> 17: c7 05 00 00 00 00 00 movl $0x0,0x0(%rip) # 21 <foo+0x21> b=0 1e: 00 00 00 21: 90 nop 22: 5d pop %rbp 23: c3 ret
如果我们采用O2级别的编译优化:
1 $ gcc -c -O2 -o compile2.o compile_demo.c
1 2 3 4 5 6 7 8 0000000000000000 <foo>: 0: f3 0f 1e fa endbr64 4: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # a <foo+0xa> a: c7 05 00 00 00 00 00 movl $0x0,0x0(%rip) # 14 <foo+0x14> b=0 11: 00 00 00 14: 83 c0 01 add $0x1,%eax 17: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 1d <foo+0x1d> 1d: c3 ret
可以摁着头皮尝试阅读一下,其实也不难看懂(我写了一句注释b=0),可以看出,b=0与a=b+1两句话在不同的编译优化上,表现出的位置实际上是不同的,这是因为在单线程下,a与b的赋值顺序在编译器看来其实无关痛痒,但在多线程并发下很可能会出问题,就比如上面的Peterson算法,如果编译器调换了循环等待与其他语句的顺序,那么Peterson算法将不再成立。
对于这个问题也存在对应的解决方案:
显式编译屏障
编译器提供了编译器屏障(compiler barriers),用来告知不可重排
1 2 3 4 5 6 7 8 9 #define barrier() asm volatile("" :::"memory" ) int a,b;void (){ a=b+1 ; barrier() b=0 ; }
显然这个宏定义也超出我的知识范围了,问问chatgpt吧:
具体而言,这个宏的定义中包含了一个内联汇编语句,这个汇编语句的作用是告诉编译器在这里插入一个内存屏障,确保前面的内存操作(读或写)和后面的内存操作在执行时的顺序不能被重排。 memory是一个内存屏障的类型,表示在这个位置之前和之后的所有内存访问不能被重排。
再次编译,反编译:
1 2 3 4 5 6 7 8 0000000000000000 <foo>: 0: f3 0f 1e fa endbr64 4: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # a <foo+0xa> a: 83 c0 01 add $0x1,%eax d: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 13 <foo+0x13> 13: c7 05 00 00 00 00 00 movl $0x0,0x0(%rip) # 1d <foo+0x1d> b=0 1a: 00 00 00 1d: c3 ret
隐式编译屏障
当某个函数包含屏障时,调用该函数也有屏障的作用
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include "thread.h" #define A 1 #define B 2 #define BARRIER __sync_synchronize() atomic_int nested; atomic_long count;void critical_section () { long cnt = atomic_fetch_add(&count, 1 ); int i = atomic_fetch_add(&nested, 1 ) + 1 ; if (i != 1 ) { printf ("%d thread in the critical section @ count=%ld\n" , i, cnt); assert(0 ); } atomic_fetch_add(&nested, -1 ); } int volatile x = 0 , y = 0 , turn; void TA () { while (1 ) { x=1 ; BARRIER; turn=B; BARRIER; while (1 ) { if (!y) break ; BARRIER; if (turn!=B) break ; BARRIER; } critical_section(); x=0 ; BARRIER; } } void TB () { while (1 ) { y=1 ; BARRIER; turn=A; BARRIER; while (1 ) { if (!x) break ; BARRIER; if (turn!=A) break ; BARRIER; } critical_section(); y=0 ; BARRIER; } } int main () { create(TA); create(TB); }
实现多线程求和(原子性)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include "thread.h" #define N 100000000 long sum =0 ;void atomic_inc (long *ptr) { asm volatile ( "lock incq %0" :"+m" (*ptr) : :"memory" ) ;} void Tsum () { for (int i = 0 ; i < N; i++) { atomic_inc (&sum); } } int main () { create(Tsum); create(Tsum); join(); printf ("sum=%ld\n" ,sum); }
总结
并发提供了新的功能,但确确实实带来了极大的实现挑战,注意理解顺序性,原子性在实现中的必要性,要明白我们写的高级代码,在运行时会出很多幺蛾子,从而更好地理解并发的进程同步。
参考链接
volatile和编译器屏障_asm
volatile("yield" ::: "memory");-CSDN博客
6.
并发控制基础 (jyywiki.cn)
single.dvi
(wisc.edu)课本阅读材料
Compiler Explorer (godbolt.org)
很好玩的编译网站