yolo系列基础学习
Yolov1
核心内容
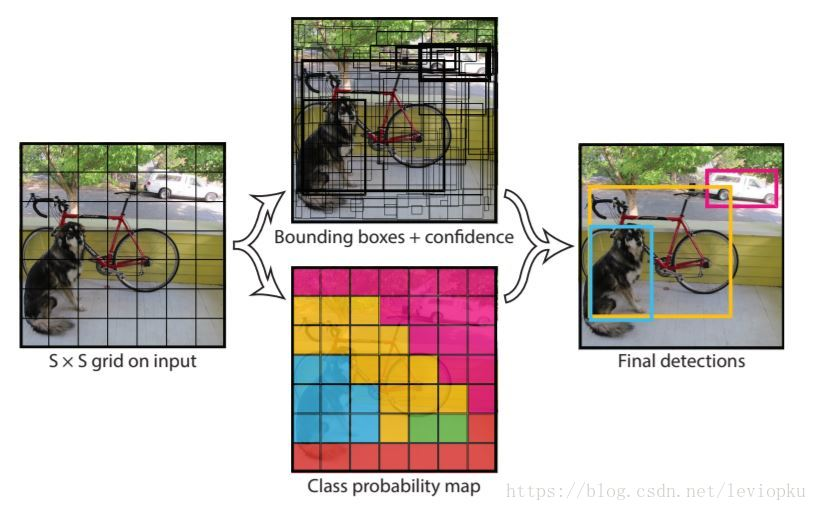
① 分而治之,其类似卷积神经网络,目的是通过分块找到物体中心,其核心思路就是一个莽,全都用CNN莽出来
②leaky ReLu \[ y=\begin{array}{l} \left\{\begin{matrix} x,x>0 \\ 0.1x,otherwise \end{matrix}\right. \end{array} \] ③ 端到端训练
Yolov2
同比v1的改进
tradeoff:折中
batch normalization:某种正则化手段,BN
high resolution classifier:微调与训练模型
Convolutional With Anchor Boxes:anchor机制
Dimension Clusters:选择anchor prior需要手动设置,采用k-means聚类找到一个合适的大小
Direct location prediction: 解决不稳定,相对位置预测
Fine-Grained Features: 调整后的yolo将在13*13的特征上做检测任务
multi-scale training:多标准化输入训练
Darknet-19:backbone网络
Yolov3
基本流程
保留部分
- 分割检测
- leaky ReLu
- 端到端训练,loss function 不变
- BN正则化不变,放在leaky ReLu和每一层卷积后
- mult scale training
基本组件
CBL:Yolov3网络结构的最小组件,由Conv+Bn+Leaky_relu组成
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成
基础操作
Concat:拼接
Add:张量相加,与shortcut功能一致
backbone
v3中没有池化层和全连接层,尺寸变换通过改变卷积和步长
backbone会将输入图片的尺寸缩短到原来的\(\frac{1}{32}\),所以要求输入图片得是32的倍数
这里要注意Darknet-19是要比Darknet-53快的,因此v3还提供了tinynet
Perdictions across scales
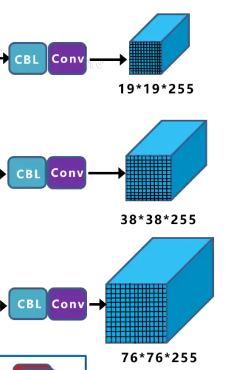
这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。规律为1:2:4